An unfair advantage - multi-tenant queues in Postgres
How we implemented fair queueing strategies for Postgres-backed task queues to ensure fair execution time across tenants.

TL;DR— we’ve been implementing fair queueing strategies for Postgres-backed task queues, so processing Bob’s 10,000 files doesn’t crowd out Alice’s 1-page PDF. We’ve solved this in Hatchet and Hatchet Cloud so you don’t have to—here’s a look at how we did it.
Introduction
We set the scene with a simple user request: they’d like to upload and parse a PDF. Or an image, CSV, audio file—it doesn’t really matter. What matters is that the processing of this file can take ages, and scales ≥ linearly with the size of the file.
Perhaps you’re an astute developer and realized that processing this file might impact the performance of your API—or more likely, the new file upload feature you pushed on Friday has you explaining to your family that nephew Jimmy’s baseball game on Saturday will have to wait.
In the postmortem, you decide to offload processing this file to somewhere outside of the core web server, asynchronously on a new worker process. The user can now upload a file, the web server quickly sends it off to the worker, and life goes on.
That is, until Bob decides to upload his entire hard drive—probably also on a Saturday—and your document processing worker now goes down.
At this point (or ideally before this point), you introduce… the task queue. This allows you to queue each file processing task and only dispatch the amount of tasks each worker can handle at a time.
But while this solves the problem of the worker crashing, it introduces a new problem, because you’ve intentionally bottlenecked the system. Which means that when Bob uploads his second hard drive, a new issue emerges—Alice’s 1-page file upload gets stuck at the back of the queue:
You’re now worried about fairness—specifically, how can you guarantee fair execution time to both Bob and Alice? We’d like to introduce a strategy that’s easy to implement in a Postgres-backed queue—and more difficult in other queueing systems—deterministic round-robin queueing.
The setup
Let’s start with some code! We’re implementing a basic Postgres-backed task queue, where workers poll for events off the queue at some interval. You can find all the code used in these examples—along with some nice helper seed and worker commands—in this repo: github.com/abelanger5/postgres-fair-queue. Note that I chose sqlc to write these examples, so you might see some sqlc.arg and sqlc.narg in the example queries.
Our tasks are very simple—they have a created_at time, some input data, and an auto-incremented id:
The query which pops tasks off the queue looks like the following:
Note the use of FOR UPDATE SKIP LOCKED: this means that workers which concurrently pull tasks off the queue won’t pull duplicate tasks, because they won’t read any rows locked by other worker transactions.
The polling logic looks something like this:
The ORDER BY id statement gives us a default ordering by the auto-incremented index. We’ve now implemented the basic task queue shared above, with long-polling for tasks. We could also add some nice features, like listen/notify to get new tasks immediately, but that’s not the core focus here.
Fair queueing
We’d now like to guarantee fair execution time to Bob and Alice. A simple way to support this is a round-robin strategy: pop 1 task from Alice, 1 task from Bob, and… Bob’s your uncle? To achieve this, we can imagine separate queues for each group of users—in this case, “purple,” “orange” and “green”:
Even though we’re essentially creating a set of smaller queues within our larger queue, we don’t want workers to manage their subscriptions across all possible queues. The ugliness of adding a new queue per group should be abstracted from the worker, which should use a single query to pop the next tasks out of the queue.
To define our groups, let’s modify our implementation above slightly: we’re going to introduce a group_key to each table:
The group key simply identifies which group the task belongs to—for example, is this one of Bob’s or Alice’s tasks? This can refer to individual users, tenants, or even a custom group key based on some combination of other fields.
First attempt: PARTITION BY
Let’s try our hand at writing a query to do this. While we have a few options, the most straightforward solution is to use PARTITION BY. Here’s what we’d like the query to look like:
This assigns a row number of 1 to the first task in each group, a row number of 2 to the second task in each group, and so on.
However, if we run this, we’ll get the error: ERROR: FOR UPDATE is not allowed with window functions (SQLSTATE 0A000) . Easy, let’s tweak our query to solve for this—we’ll load up the rows with PARTITION BY and pass them to a new expression which uses SKIP LOCKED:
… but not so fast. We’ve introduced an issue by adding the first CTE (Common Table Expression—the queries using the WITH clause). If we run 3 workers concurrently and log the number of rows that each worker receives, with a limit of 100 rows per worker, we’ll find only 1 worker is picking up tasks, even if there are more rows to return!
What’s happening here? By introducing the first CTE, we are now selecting locked rows which are excluded by FOR UPDATE SKIP LOCKED in the second CTE—in other words, we might not enqueue any runs on some workers if we’re polling concurrently for new tasks. While we are still guaranteed to enqueue in the manner which we’d like, we may reduce throughput if there’s high contention among workers for the same rows.
Unfortunately, using PARTITION BY isn’t the right approach here. But before we dive into a better approach, this query does show some interesting properties of queueing systems more generally.
Aside: queueing woes
A hotfix for the slow polling query would be adding 3 lines of code to our worker setup:
Which gives us much more promising output:
This works—and you can modify this logic to be more distributed by maintaining a lease when a worker starts for a set amount of time—as long as the polling interval is below the query duration time (or more specifically, pollingTime / numWorkers is below the query duration time). But what happens when our queue starts to fill up? Let’s add 10,000 enqueued tasks and run an EXPLAIN ANALYZE for this query to take a look at performance:
The important part here is the WindowAgg cost—computing a partition across all rows on the groupKey naturally involves querying every QUEUED row (in this case, 10000 tasks). We expect this to scale sublinearly with the number of rows in the input—let’s take a guess and look at how our workers do on 25,000 enqueued rows:
Sure enough, because we’re seeing execution times greater than 333ms, we start losing tasks on worker 1. This is very problematic, because not only is our queue backlog increasing, but the throughput of our workers is decreasing, and this isn’t a problem we can solve by throwing more workers at the queue. This is a general problem in systems that are stable for a long time until some external trigger (for example, workers going down for an hour) causes the system to fail in an unexpected way, leading to the system being unrecoverable.
A second practical solution to this issue is to create an OVERFLOW status on the task queue, and set an upper bound on the number of enqueued tasks, to ensure worker performance doesn’t drop below a certain threshold. We then can periodically check the overflow queue and place the overflow into the queued status. This is a good idea regardless of the query we write to get new tasks.
But practical advice aside, let’s take a look at how to write this query to avoid performance degradation at such a small number of enqueued tasks.
Improving performance
Sequencing algorithm
The main issue, as we’ve identified, is the window function which is searching across every row that is QUEUED. What we were hoping to accomplish with the partition method was filling up each group’s queue, ordering each group by the task id, and order the tasks by their rank within each group.
Our goal is to write a query that is constant-time (or as close as possible to constant-time) when reading from the queue, so we can avoid our system being unrecoverable. Even using a JOIN LATERAL instead of PARTITION BY will get slower as the number of partitions (i.e. groups) increases. Also, maintaining each task’s rank after reads (for example, decrementing the task’s rank within the group after read) will also get slower the more tasks we add to a group.
What if instead of computing the rank within the group via the PARTITION BY method at read time, we wrote a sequence number at write time which guarantees round-robin enqueueing? At first glance, this seems difficult—we don’t know that Alice will need to enqueue 1 task in the future if Bob enqueued 10,000 tasks now.
We can solve for this by reserving contiguous blocks of IDs for future enqueued runs which belong to groups which don’t exist yet or don’t have a task assigned for that block yet. We’re going to partition BIGINT (max=9,223,372,036,854,775,807) into blocks of blockLength:
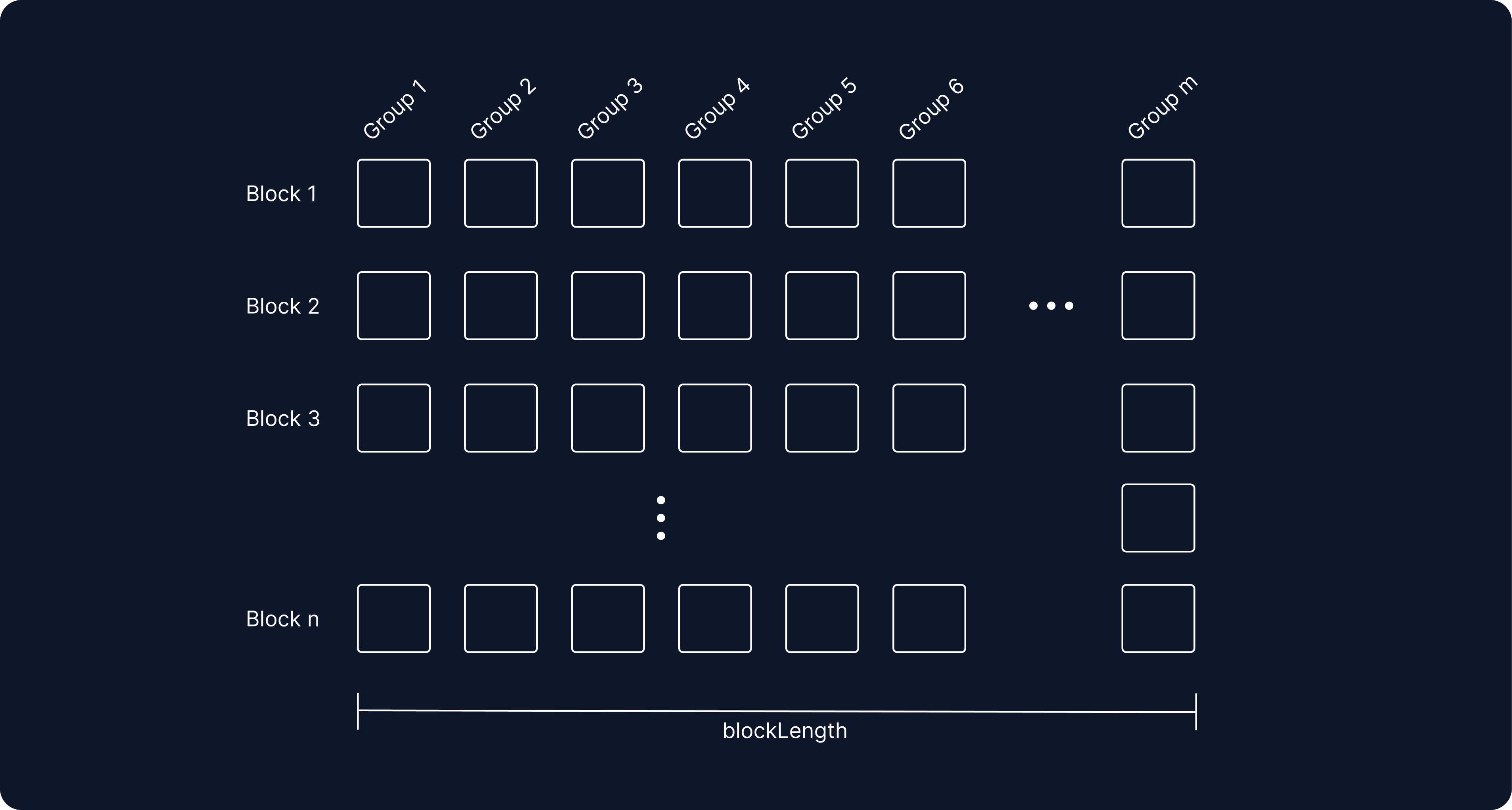
Next, let’s assign task IDs according to the following algorithm:
- Maintain a unique numerical id
ifor each distinct group, and maintain a pointerpto the last block that was enqueued for each group—we’ll call thisp(i). - Maintain a pointer
pto the block containing the maximum task ID which doesn’t have aQUEUEDstatus (in other words, the maximum assigned task), call thisp_max_assigned. If there are no tasks in the queue, set this to the maximum block across allp(i). Initializep_max_assignedat 0. - When a task is created in group
j:- If this is a new group
jis added, initializep(j)top_max_assigned - If this is an existing group
j, setp(j)to the greater ofp_max_assignedorp(j) + 1 - Set the id of the task to
j + blockLength * p(j)
- If this is a new group
Note: we are making a critical assumption that the number of unique group keys will always be below the
blockLength, and increasing the blockLength in the future would be a bit involved. A blockLength of ~1 million gives us ~1 billion task executions. To increase the block length, it’s recommended that you add an offset equal to the the maximum task id, and start assigning task ids from there. We will also (in the worst case) cap out at 1 billion executed tasks, though this can be fixed by reassigning IDs when close to this limit.
SQL implementation
To actually implement this, let’s add a new set of tables to our queue implementation. We’ll add a table for task_groups, which maintains the pointer p(i) from above, along with a table called task_addr_ptrs which maintains p_max_assigned from above:
Next, we’ll write our CreateTask query using a blockLength of 1024*1024:
The great thing about this is that our PopTasks query doesn’t change, we’ve just changed how we assign IDs. However, we do need to make sure to update task_addr_ptrs in the same transaction that we pop tasks from the queue:
Against 1 million enqueued tasks with 1000 partitions, we still only need to search across 100 rows:
You may also have noticed that because we stopped using the window function, we’ve removed the issue of selecting for previously locked rows. So even if we start 10 workers at the same time, we’re guaranteed to select unique rows again:
This doesn’t come without a tradeoff: our writes are slower due to continuously updating the block_addr parameter on the task_group. However, even the writes are constant-time, so the throughput on writes is still on the order of 500 to 1k tasks/second. If you’d prefer a higher write throughput, setting a small limit for placing tasks in the OVERFLOW queue and using the partition method from above may be a better approach.
Introducing concurrency limits
In the above implementation, we had a simple LIMIT statement to set an upper bound of the number of tasks a worker should execute. But what if we want to set a concurrency limit for each group of tasks? For example, not only do we want to limit a worker to 100 tasks globally, but we limit each group to 5 concurrent tasks (we’ll refer to this number as concurrency below). This ensures that even if there are slots available on the worker, they are not automatically filled by the same user, which could again crowd out other users in the near future.
Luckily, this is quite simple with the implementation above. Because of the way we’ve divided task ids across different block addresses, we can simply limit concurrency by searching only from the minimum queued ID min_id to min_id + blockLength * concurrency:
This guarantees an additional level of fairness which makes it even harder for Bob’s workloads to interfere with Alice’s.
Final thoughts
We’ve covered deterministic round-robin queueing, but it turns out that many systems just need approximate fairness guarantees (“deterministic” in this case refers to the fact that tasks are processed in a deterministic order on subsequent reads—as opposed to using something like ORDER BY RANDOM()). But there are other approaches which provide approximate fairness, such as shuffle sharding, which we’ll show how to implement in Postgres in a future post.
If you have suggestions on making these queries more performant—or perhaps you spotted a bug—I’d love to hear from you in our Discord.
Hatchet Cloud is our managed Hatchet offering. Give it a spin and let us know what you think!